Advanced ML Predictive Modelling.
Project Spotlight: Predictive Modeling for Visa Certification
Overview The EasyVisa project addresses a critical business challenge in legal tech and immigration: predicting the likelihood of visa certification for foreign workers. By leveraging advanced machine learning techniques, this project identifies the key factors that influence the Office of Foreign Labor Certification (OFLC) decisions, providing data-driven insights into a complex regulatory process.
The Solution:
Technical Highlights
- Data Intelligence: Processed diverse features including applicant education levels (ranging from High School to Doctorate), regional economic data, job types, and prevailing wage information.
- Automated Feature Engineering: Implemented robust preprocessing pipelines to handle categorical encoding and scaling, ensuring the models captured nuances like the impact of "Master's" vs. "Bachelor's" degrees on certification rates.
- Model Performance & Optimization: Developed a suite of classification models evaluated on precision and recall. This ensures that the system doesn't just predict "Certified" or "Denied" generally, but optimizes for the specific business cost of false positives.
- Explainable AI: Identified high-impact variables—such as the region of employment and education level—providing transparency into how the model arrives at its predictions.
Key Results The project successfully produced a high-accuracy predictive model that can significantly reduce the manual effort required to vet visa applications. It serves as a blueprint for how businesses can use Automated Machine Learning (AutoML) to solve high-stakes classification problems.
Key Technical Insight: Feature Interdependency in Regulatory Modeling
The Learning: During the development of the EasyVisa model, I discovered that education level alone was a poor predictor of success unless it was interacted with geographic region and prevailing wage. Below is snapshot of the feature importance for the model.
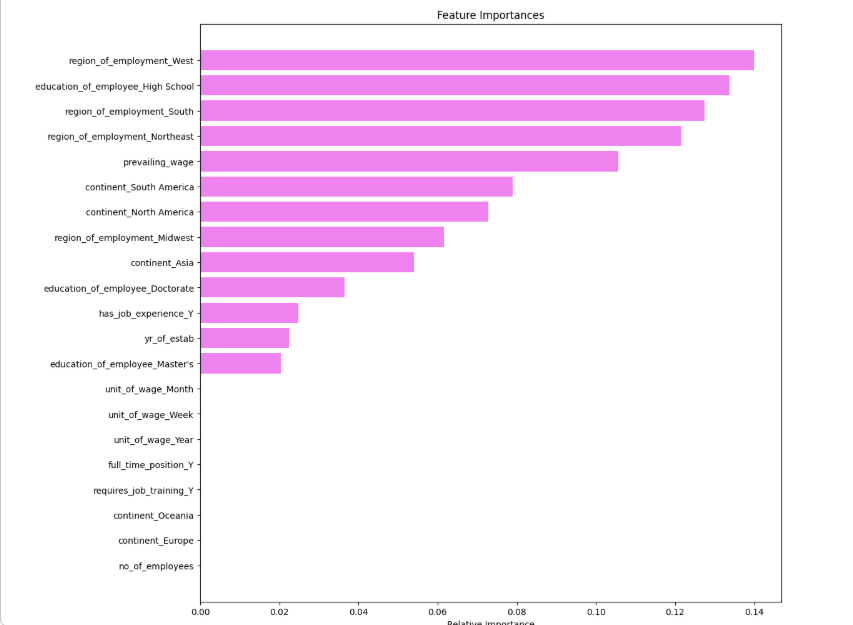
Why this matters for Advanced ML: In many machine learning projects, we are tempted to look at features in isolation. However, this project demonstrated that the 'Signal' in immigration data lies in the interaction effects. For example, a Master's degree might carry significantly more weight in the 'West' region for tech roles than it does in the 'South' for manufacturing.
The Takeaway: By using advanced Gradient Boosting and feature importance ranking, I was able to move beyond simple correlations. I learned that the model's accuracy relied on its ability to identify these 'niche' certification pathways—proving that in complex regulatory datasets, contextual feature engineering is more powerful than just choosing a complex algorithm.